Индексация и срезы
Строки, списки и кортежи являются упорядоченными коллекциями, то есть их элементы имеют фиксированный порядок и свои собственные порядковые номера, называемые индексами. С их помощью можно как получать отдельные элементы коллекции, так и извлекать целые последовательности элементов.
Получение элементов по индексу
По индексу можно получить отдельные элементы строк, списков и кортежей. Например, у нас есть следующие переменные:
message_str = "Как дела?" # Строка
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"] # Список
friends_tuple = ("Друг 1", "Друг 2", "Друг 3") # Кортеж
Первый символ "К" строки "Как дела?" находится по индексу 0, второй символ "а" – по индексу 1, и так далее.
При этом можно использовать не только положительные, но отрицательные индексы, которые позволяют обращаться к элементам с конца коллекции. В таком случае последний элемент "Друг 3" кортежа friends имеет индекс -1, предпоследний – -2, и так далее.
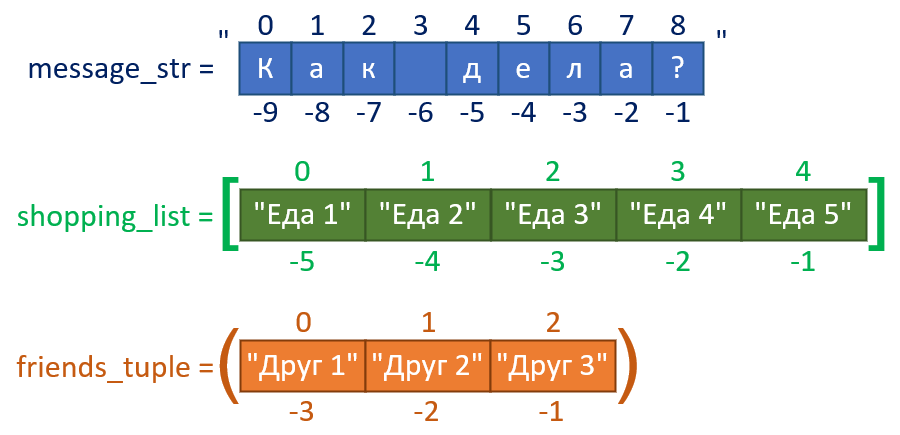
Чтобы получить элемент по его индексу, нужно указать имя переменной, содержащей коллекцию, и нужный индекс в квадратных скобках:
коллекция[индекс]
Так мы можем получить отдельные символы строки и элементы списка и кортежа:
message_str = "Как дела?"
print(message_str[0])
# Вывод: К
print(message_str[3])
# Вывод: (Пробел тоже является отдельным символом)
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[4])
# Вывод: Еда 5
print(shopping_list[-3])
# Вывод: Еда 3
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[0])
# Вывод: Друг 1
print(friends_tuple[-3])
# Вывод: Друг 1
Попытка обратиться к элементу по несуществующему индексу приведет к исключению IndexError:
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[9])
# Ошибка: IndexError: tuple index out of range
Использование срезов
Для извлечения не одного элемента, а сразу целого подмножества элементов строки, списка и кортежа в Python предусмотрен удобный механизм срезов. Срез позволяет получить часть коллекции в соответствии с заданными параметрами:
коллекция[start:stop:step]
Параметрами среза любой коллекции являются:
start– начальный индекс среза (включительно), по умолчаниюstart=0.stop– конечный (не включительно) индекс среза.step– шаг извлечения элементов, по умолчаниюstep=1.

Срезы, как и функция range(), используют параметры start, stop и step, и одинаково задают границы и шаг получения элементов. Однако срезы применяются непосредственно к строкам, спискам и кортежам, позволяя выбирать их подмножества, тогда как range() создает отдельную последовательность целых чисел. При этом создаваемая последовательность чисел соответствует индексам, выбираемым в срезе. То есть, задавая функции range() границы и шаг, вы получаете именно те индексы, которые будут использованы при формировании среза с такими же параметрами.
Срез коллекции представлен тем же типом данным, что и сама коллекция: срезом строки будет строка (называемая подстрокой), срезом списка – список, а срезом кортежа – кортеж.
Ни один из параметров среза не является обязательным, поэтому без учёта шага возможны следующие конструкции получения среза коллекции:
[:] – выбирает всю коллекцию целиком:
message_str = "Как дела?"
message_str_copy = message_str[:]
print(message_str_copy)
# Вывод: Как дела?
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
shopping_list_copy = shopping_list[:]
print(shopping_list_copy)
# Вывод: ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
friends_tuple_copy = friends_tuple[:]
print(friends_tuple_copy)
# Вывод: ("Друг 1", "Друг 2", "Друг 3")
[start:] – выбирает элементы от индекса start до конца коллекции.
message_str = "Как дела?"
print(message_str[4:])
# Вывод: дела?
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[2:])
# Вывод: ['Еда 3', 'Еда 4', 'Еда 5']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[1:])
# Вывод: ('Друг 2', 'Друг 3')
[:stop] – выбирает элементы от начала коллекции до индекса stop (не включая его):
message_str = "Как дела?"
print(message_str[:3])
# Вывод: Как
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[:2])
# Вывод: ['Еда 1', 'Еда 2']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[:2])
# Вывод: ('Друг 1', 'Друг 2')
[start:stop] – выбирает все элементы с индекса start по индекс stop (не включая его):
message_str = "Как дела?"
print(message_str[0:3])
# Вывод: Как
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[2:4])
# Вывод: ['Еда 3', 'Еда 4']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[1:3])
# Вывод: ('Друг 2', 'Друг 3')
Кроме того, в срезах разрешается использовать отрицательные индексы и даже совмещать их с положительными:
message_str = "Как дела?"
print(message_str[-9:-6])
# Вывод:Как
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[-4:5])
# Вывод: ['Еда 2', 'Еда 3', 'Еда 4', 'Еда 5']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[-2:])
# Вывод: ('Друг 2', 'Друг 3')
Шаг извлечения элементов
Параметр step всегда указывается после второго двоеточия и определяет шаг извлечения элементов из коллекции. По умолчанию step=1, то есть элементы извлекаются последовательно слева направо. Но если указать step=2, то будет извлечён каждый второй элемент:
message_str = "Как дела?"
print(message_str[::2])
# Вывод: Ккдл?
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[::2])
# Вывод: ['Еда 1', 'Еда 3', 'Еда 5']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[::2])
# Вывод: ('Друг 1', 'Друг 3')
Здесь мы не указывали параметры start и stop, поэтому в срез была извлечена вся коллекция.
Для получения элементов с нечетными индексами можно начать срез с индекса 1:
message_str = "Как дела?"
print(message_str[1::2])
# Вывод: а еа
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[1::2])
# Вывод: ['Еда 2', 'Еда 4']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[1::2])
# Вывод: ('Друг 2',)
Использование отрицательного шага, например step=-1, позволяет получить коллекцию в обратном порядке:
message_str = "Как дела?"
print(message_str[::-1])
# Вывод: ?алед каК
shopping_list = ["Еда 1", "Еда 2", "Еда 3", "Еда 4", "Еда 5"]
print(shopping_list[::-1])
# Вывод: ['Еда 5', 'Еда 4', 'Еда 3', 'Еда 2', 'Еда 1']
friends_tuple = ("Друг 1", "Друг 2", "Друг 3")
print(friends_tuple[::-1])
# Вывод: ('Друг 3', 'Друг 2', 'Друг 1')
Индексация во вложенных коллекциях
Коллекции могут содержать другие коллекции, создавая вложенные структуры. Например, рассмотрим кортеж, содержащий два списка:
cities = (
["Москва", "Санкт-Петербург"],
["Череповец", "Вологда"]
)
print(cities[1][0])
# Вывод: Череповец
Для доступа к элементам вложенных списков используется двойная индексация. Первый индекс 1 обращается ко второму элементу кортежа: списку ["Череповец", "Вологда"], а второй индекс 0 – к первому элементу этого вложенного списка: строке "Череповец".
Уровень вложенности может быть любым, так что возможно использование трёх индексов и более.
Также из вложенных коллекций можно извлекать срезы:
cities = (
["Москва", "Санкт-Петербург"],
["Череповец", ["Вологда", "Шексна", "Устюжна"]]
)
print(cities[1][1][:2])
# Вывод: ['Вологда', 'Шексна']
Рассмотрим элементы, получаемые с помощью такого индекса:
cities[1]– возвращает второй элемент кортежаcities: список["Череповец", ["Вологда", "Шексна", "Устюжна"]].cities[1][1]– возвращает второй элемент первого вложенного списка:список ["Вологда", "Шексна", "Устюжна"].cities[1][1][:2]– возвращает срез второго вложенного списка: список["Вологда", "Шексна"]
Примеры
Пример 1. Обработка логов
Логи сервера хранятся в формате «[2025-01-25 14:30:45] ERROR: Connection timeout». Для их обработки программа с помощью срезов выделяет дату и событие в отдельные переменные:
log_entry = "[2025-01-25 14:30:45] ERROR: Connection timeout"
# Извлечение даты и времени
timestamp = log_entry[1:20] # Срез символов с 1 по 19
event = log_entry[22:] # Всё после 22 символа
print(f"Дата: {timestamp}")
print(f"Событие: {event}")
Вывод:
Дата: 2025-01-25 14:30:45
Событие: ERROR: Connection timeout
Пример 2. Анализ среднесуточной температуры в июне
При анализе среднесуточной температуры июне для экспериментов требуется только часть общего объёма данных, которая копируется с помощью среза:
# Данные по среднесуточной температуре в июне
temperatures = [18.5, 23.1, 22.3, 25.7, 21.9, 25.6, 27.4, 21.2, 21.3, 20.9, 35.7, 21.8, 24.1, 29.6, 28.9, 20.5, 26.8, 25.3, 27.1, 23.2, 24.4, 22.6, 21.7, 23.8, 20.5, 20.3, 21.9, 26.4, 21.2, 21.5]
# Скопируем небольшой участок данных для экспериментов
sample_data = temperatures[:10]
# Изменим последний элемент образца данных
sample_data[-1] += 10
print("Образец модифицированных данных:", sample_data)
print("Образец исходных данных:", temperatures[:10])
Вывод:
Образец модифицированных данных: [18.5, 23.1, 22.3, 25.7, 21.9, 25.6, 27.4, 21.2, 21.3, 30.9]
Образец исходных данных: [18.5, 23.1, 22.3, 25.7, 21.9, 25.6, 27.4, 21.2, 21.3, 20.9]
Пример 3. Проверка палиндромов
Онлайн-сервис предоставляет возможно проверить, является ли введённая строка палиндромом. То есть строкой, читающейся одинаково слева направо и справа налево (например, «заказ», «шалаш»):
s = input("Введите слово: ")
reverse_s = s[::-1] # Строка в обратном порядке
if s == reverse_s:
print("Строка является палиндромом")
else:
print("Строка не является палиндромом")
Вывод:
Введите слово: мадам
Строка является палиндромом
Итоги
- Индекс – это порядковый номер элемента в упорядоченной коллекции (строке, списке и кортеже). С помощью индекса можно получить символ строки или элемент списка или кортежа.
- Положительные индексы начинаются с 0, отсчитывая элементы с начала коллекции, а отрицательные индексы начинаются с -1, отсчитывая элементы с конца.
- Конструкция
[start:stop:step]позволяет получить срез коллекции в соответствии с заданными параметрами:startзадаёт начальный индекс среза (включительно),stop– конечный индекс (не включительно), аstep– шаг извлечения элементов. Ни один из параметров не является обязательным. - Индексы и срезы применимы ко вложенным коллекциям. Уровень вложенности не ограничен.
Задания для самопроверки
1. Дан список numbers = [10, 20, 30, 40, 50]. Как получить третий элемент списка? Используйте как положительный, так и отрицательный индекс.
numbers = [10, 20, 30, 40, 50]
print(numbers[2])
# Вывод: 30
print(numbers[-3])
# Вывод: 30
Третий элемент списка находится по положительному индексу 2, и по отрицательному индексу -3.
2. Дан кортеж fruits = (["Яблоко", "Банан"], ["Апельсин", "Киви"]). Используйте индексы и выведите на экран строку "Банан".
fruits = (["Яблоко", "Банан"], ["Апельсин", "Киви"])
print(fruits[0][1])
# Вывод: Банан
3. Дан список colors = ["Красный", "Оранжевый", "Жёлтый", "Зелёный", "Голубой", "Синий", "Фиолетовый"]. Какие срезы получатся, если использовать следующие конструкции:
colors[2:]
colors[1:4]
colors[-5:2]
colors[1::2]
colors[-2:-6:-1]
colors = ["Красный", "Оранжевый", "Жёлтый", "Зелёный", "Голубой", "Синий",
"Фиолетовый"]
print(colors[2:])
# Вывод: ['Жёлтый', 'Зелёный', 'Голубой', 'Синий', 'Фиолетовый']
print(colors[1:4])
# Вывод: ['Оранжевый', 'Жёлтый', 'Зелёный']
print(colors[2:-2])
# Вывод: ['Жёлтый', 'Зелёный', 'Голубой']
print(colors[1::2])
# Вывод: ['Оранжевый', 'Зелёный', 'Синий']
print(colors[-2:-6:-1])
# Вывод: ['Синий', 'Голубой', 'Зелёный', 'Жёлтый']
4. Дана строка sentence = "Весна, весна на улице, весенние деньки!". Выведите на экран строку, состоящую из каждого третьего символа этой строки.
sentence = "Весна, весна на улице, весенние деньки!"
new_sentence = sentence[2::3]
print(new_sentence)
# Вывод: с,еаалевеидь!
5. Измените порядок символов в строке user = "радар", записав её задом наперёд с помощью среза.
user = "радар"
print(user[::-1])
# Вывод: радар
0 комментариев